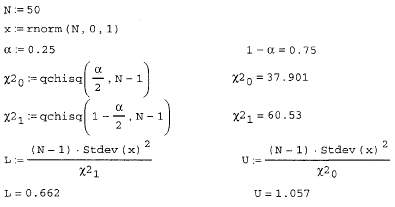13.4.2. Проверка статистических гипотез*
В статистике рассматривается огромное число задач, связанных с проверкойтех или иных гипотез н. Разберем пример простой гипотезы. Пусть имеетсявыборка N чисел с нормальным законом распределения и неизвестнымидисперсией и математическим ожиданием. Требуется принять или отвергнуть гипотезу н о том, что математическое ожидание закона распределенияравно некоторому числу мюО=о.2.
Задачи проверки гипотез требуют задания уровня критерия проверки гипотезы а, который описывает вероятность ошибочного отклонения истинной н.Если взять а очень малым, то гипотеза, даже если она ложная, будет почтивсегда приниматься; если, напротив, взять а близким к 1, то критерий будеточень строгим, и гипотеза, даже верная, скорее всего, будет отклонена.В нашем случае гипотеза состоит в том, что мюо=о.2, а альтернатива- чтомю0 неравно 0.2. Оценка математического ожидания, как следует из курса классической статистики, решается с помощью распределения Стьюдента с параметром N-I (этот параметр называется степенью свободы распределения).
Для проверки гипотезы (листинг 13.22) рассчитывается (а/2) - квантильраспределения Стьюдента т, который служит критическим значением дляпринятия или отклонения гипотезы. Если соответствующее выборочноезначение t по модулю меньше т, то гипотеза принимается (считается верной). В противном случае гипотезу следует отвергнуть.
Листинг 13.22. Проверка гипотезы о математическом ожиданиипри неизвестной дисперсии
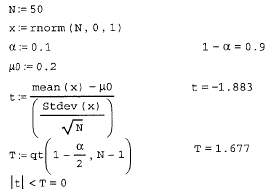
В последней строке листинга вычисляется истинность или ложность условия, выражающего решение задачи. Поскольку условие оказалось ложным(равным не 1, а 0), то гипотезу необходимо отвергнуть.
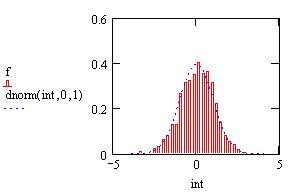
На рис. 13.16 показано распределение Стьюдента с N-I степенью свободы,вместе с критическими значениями, определяющими соответствующий интервал. Если t (оно тоже показано на графике) попадает в него, то гипотезапринимается; если не попадает (как произошло в данном случае) - отвергается. Если увеличить а, ужесточив критерий, то границы интервала будутсужаться, по сравнению с показанными на рисунке.
В листинге 13.23 приводится альтернативный способ проверки той же самойгипотезы, связанный с вычислением значения не квантиля, а самого распределения Стьюдента.
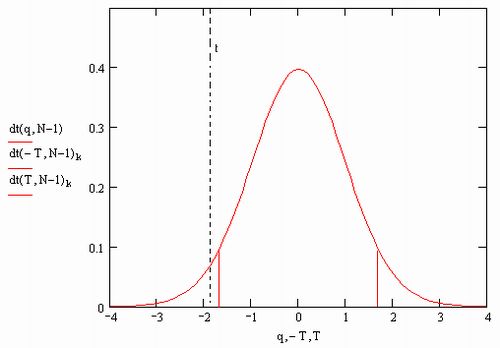
Рис. 13.16. К задаче проверки статистических гипотез (листинг 13.22)
Листинг 13.23. Другой вариант проверки гипотезы(продолжение листинга 13.22)
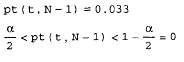
Мы разобрали только два характерных примера статистических вычислений.Однако с помощью MathCAD легко решаются самые разнообразные задачиматематической статистики.
Примечание
Большое количество задач разобрано в Центре Ресурсов в рубрике Statistics(Статистика).
Глава 12
Содержание
Глава 14
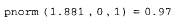
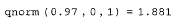
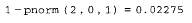
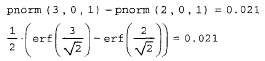

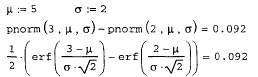


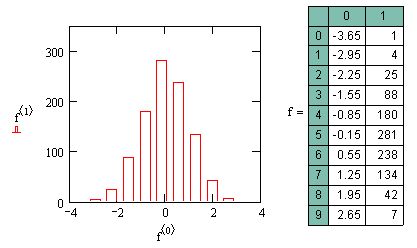
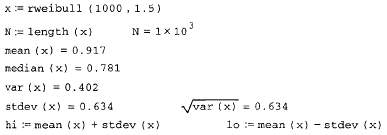
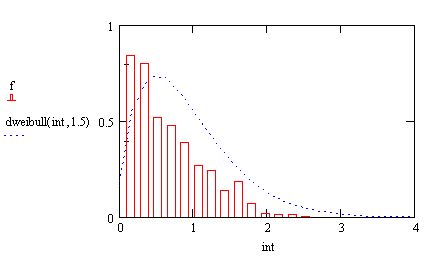

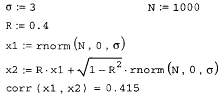
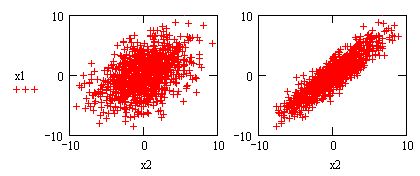
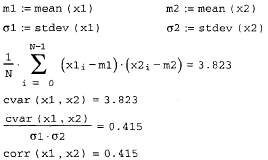
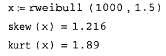
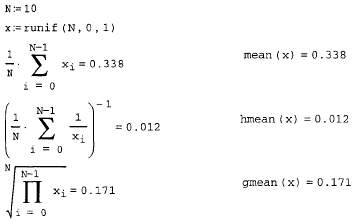
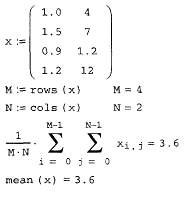

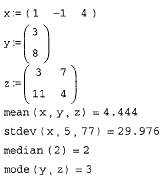

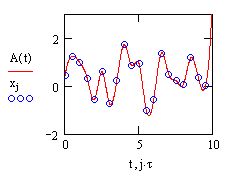
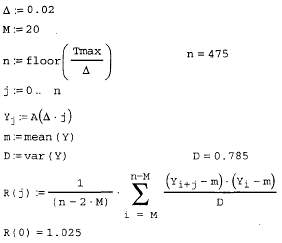 и вычисление корреляционной функции (продолжение листинга 13.19)
и вычисление корреляционной функции (продолжение листинга 13.19)