|
|
ОСНОВНЫЕ ПОНЯТИЯОбщие положенияЦель любой информационной системы - обработка данных об объектах реального мира. В широком смысле слова база данных - это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области. Под предметной областью принято понимать часть реального мира, подлежащего изучению для организации управления и в конечном счете автоматизации, например, предприятие, вуз и т.д. Создавая базу данных, пользователь стремится упорядочить информацию по различным признакам и быстро извлекать выборку с произвольным сочетанием признаков. Сделать это возможно, только если данные структурированы. Структурирование -этовведение соглашений о способах представления данных. Неструктурированными называют данные, записанные, например, в текстовом файле. Пример 15.1. Пример неструктурированных данных, содержащих сведения о студентах (Номер личного дела, фамилию, имя, отчество и год рождения). Легко убедиться, что сложно организовать поиск необходимых данных, хранящихся в неструктурированном виде, а упорядочить подобную информацию практически не представляется реальным. Личное дало N 16493, Сергеев Петр Михайлович, дата рождения 1 января 1876 г; Л/д. N 16593. Петрова Анна Владимировна, дата рожд. 15 марта 1975 г; N личн. дела 16693, д.р. 14.04,78, Анохин Андрей Борисович. Чтобы автоматизировать поиск и систематизировать эти данные, необходимо выработать определенные соглашения о способах представления данных, т.е. дату рождения нужно записывать одинаково для каждого студента, она должна иметь одинаковую длину и определенное место среди остальной информации. Эти же замечания справедливы и для остальных данных (номер личного дела, фамилия, имя. отчество). Пример 15.2. После проведения несложной структуризации с информацией, указанной в примере (рис. 15.1), она будет выглядеть так, как это показано на рис. 15.2.
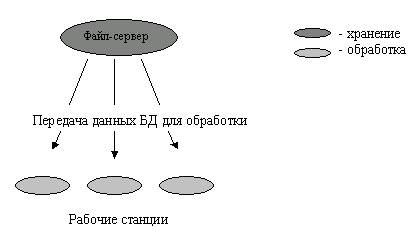
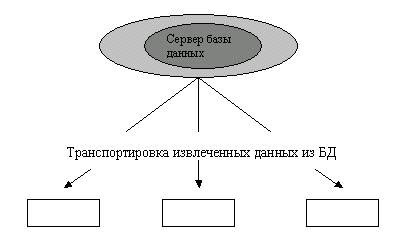
Рис. 15.2. Пример структурированных данных Пользователями базы данных могут быть различные прикладные программы, программные комплексы, а также специалисты предметной области, выступающие в роли потребителей или источников данных, называемые конечными пользователями. В современной технологии баз данных предполагается, что создание базы данных, ее поддержка и обеспечение доступа пользователей к ней осуществляются централизованно с помощью специального программного инструментария - системы управления базами данных. База данных (БД) - это поименованная совокупность структурированные данных, относящихся к определенной предметной области. Система управления базами данных (СУБД) - это комплекс программных и языковых средств, необходимых для создания баз данных, поддержания их в актуальном состоянии и организации поиска в них необходимой информации. Централизованный характер управления данными в базе данных предполагает необходимость существования некоторого лица (группы лиц), на которое возлагаются функции администрирования данными, хранимыми в базе. Классификация баз данныхПо технологии обработки данных базы данных подразделяются на централизованные и распределенные. Централизованная база данныххранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети ЭВМ, возможен распределенный доступ к такой базе. Такой способ использования баз данных часто применяют в локальных сетях ПК. Распределенная база данных состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базой данных (СУРБД). По способу доступа к данным базы данных разделяются на базы данных слокальным доступом и базы данных с удаленным (сетевым доступом). Системы централизованных баз данных с сетевым доступом предполагают различные архитектуры подобных систем: • файл-сервер; • клиент-сервер. Файл-сервер. Архитектура систем БД с сетевым доступом предполагает выделение одной из машин сети в качестве центральной (сервер файлов). На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользовательской системы к централизованной базе данных. Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. При большой интенсивности доступа к одним и темже данным производительность информационной системы падает. Пользователи могут создавать также на рабочих станциях локальные БД, которые используютсяими монопольно. Концепция файл-сервер условно отображена на рис. 15.3. Клиент-сервер. В этой концепции подразумевается, что помимо хранения централизованной базы данных центральная машина (сервер базы данных) должна обеспечивать выполнение основного объема обработки данных. Запрос на данные, выдаваемый клиентом (рабочей станцией), порождаетпоиск и извлечение данных на сервере. Извлеченные данные (но не файлы) транспортируются по сети от сервера к клиенту. Спецификой архитектуры клиент-сервер является использование языка запросов SQL. Концепция клиент-сервер условно изображена на рис.15.4
Рис.15.3. Схема обработки информации в БД по принципу файл-сервер
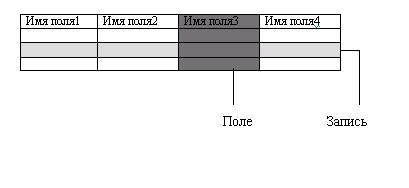
Рис.15.4. Схема обработки информации в БД по принципу клиент-сервер Структурные элементы базы данныхПонятие базы данных тесно связано с такими понятиями структурных элементов, как поле, запись, файл (таблица) (рис. 15.5). п о л е, - элементарная единица логической организации данных, которая соответствует неделимой единице информации - реквизиту. Для описания поля используются следующие характеристики: и м я, например. Фамилия, Имя, Отчество, Дата рождения; т и п, например, символьный, числовой, календарный; д л и и а, например, 15 байт, причем будет определяться максимально возможнымколичеством символов т о ч н о с т ь, для числовых данных, например два десятичныхзнака для отображения дробной части числа. Рис. 15.5.Основные структурные элементы БД Запись - совокупность логически связанных полей. Экземпляр записи - отдельная реализация записи, содержащая конкретные значения ее полей. Файл (таблица) - совокупность экземпляров записей одной структуры. Описание логической структуры записи файла содержит последовательность расположения полей записи и их основные характеристики, как это показано на рис.15.6.
Рис. 15.6.Описание логической структуры записи файла В структуре записи файла указываются поля, значения которых являются ключами: первичными (ПК), которые идентифицируют экземпляр записи, и вторичными (ВК), которые выполняют роль поисковых или группировочных признаков (по значению вторичного ключа можнонайти несколько записей). Пример 15.3. На рис. 15.7приведен пример описания логической структуры записи файла(таблицы) студент, содержимое которого приводится на рис 15.2. Структура записи файла СТУДЕНТ линейная, она содержит записи фиксированной длины. Повторяющиеся группы значений полей в записи отсутствуют. Обращение к значению поля производится по его номеру.
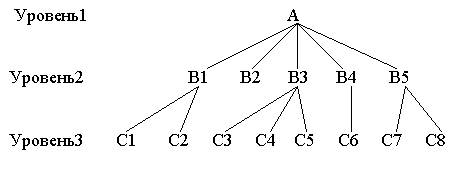
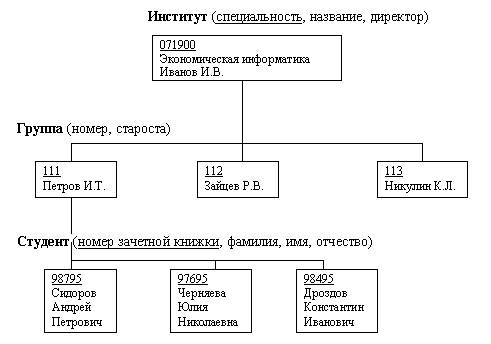
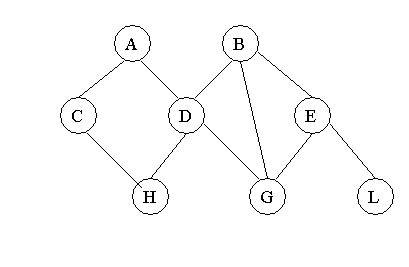
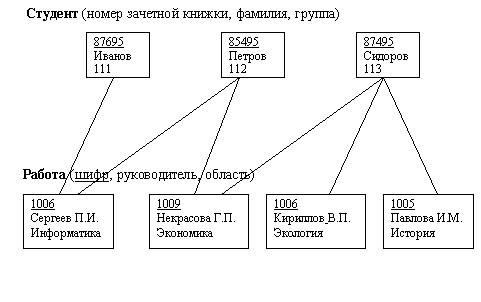
Рис. 15.7. Описание логической структуры записи файла СТУДЕНТ ВИДЫ МОДЕЛЕЙ ДАННЫХОбщие положенияЯдром любой базы данных является модель данных. Модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи междуними. Модель данных - совокупность структур данных и операций их обработки. СУБД основывается на использовании иерархической, сетевой или реляционной модели, на комбинации этих моделей или на некотором их подмножестве [1]. Рассмотрим три основных типа моделей данных: иерархическую, сетевую и реляционную. Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево), вид которого представлен на рис. 15.8. К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь. Узел - это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей. К каждой записи базы данных существует только один (иерархический) путь от корневой записи. Например, как видно из рис. 15.8, для записи С4 путь проходит через записи А и ВЗ. Рис. 15.8. Графическое изображение иерархической структуры БД Пример 15.4. Пример, представленный на рис. 15.9. иллюстрирует использование иерархической модели базы данных. Для рассматриваемого примера иерархическая структура правомерна, так как каждый студент учится в определенной (только одной) группе, которая относится к определенному (только одному) институту. Сетевая модель данныхВ сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом, На рис. 15.10 изображена сетевая структура базы данных в виде графа. Пример 15.5. Примером сложной сетевой структуры может служить структура базы данных, содержащей сведения о студентах, участвующих в научно-исследовательских работах (НИРС). Возможно участие одного студента в нескольких НИРС, а также участие нескольких студентов в разработке одной НИРС. Графическое изображение описанной в примересетевой структуры, состоящей только из двух типов записей, показано на рис. 15.11.Единственное отношение представляет собой сложную связь между записями в обоих направлениях. Рис. 15.9. Пример иерархической структуры БД Рис. 15.10. Графическое изображение сетевой структуры Рис. 15.11.Пример сетевой структуры БД Понятие реляционный (англ.relation - отношение) связано с разработками известного американского специалиста в области систем баз данных Е. Кодда. Эти модели характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных. Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами: каждый элемент таблицы - один элемент данных; все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину; каждый столбец имеет уникальное имя; одинаковые строки в таблице отсутствуют; порядок следования строк и столбцов может быть произвольным. Пример 15.6. Реляционной таблицей можно представить информацию о студентах, обучающихся в вузе (рис. 15.12).
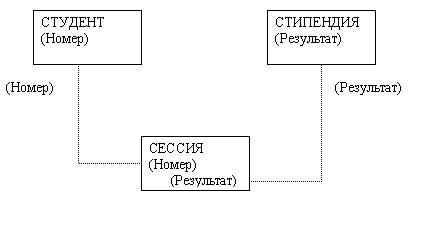
Рис. 15.12. Пример реляционной таблицы Отношения представлены в виде таблиц, строки которых соответствуют кортежам или записям, а столбцы - атрибутам отношений, доменам, полям. Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом (ключевым полем). Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составной ключ. В примере, показанном на рис. 15.12, ключевым полем таблицы является "N личного дела". Чтобы связать две реляционные таблицы, необходимо ключ первой таблицы ввести в состав ключа второй таблицы (возможно совпадение ключей); в противном случае нужно ввести в структуру первой таблицы внешний ключ - ключ второй таблицы. Пример 15.7. На рис. 15.13 показан пример реляционной модели, построенной на основе отношений: СТУДЕНТ, СЕССИЯ, СТИПЕНДИЯ. Рис.15.13. Пример реляционной модели СТУДЕНТ (Номер, Фамилия, Имя, Отчество, Пол, Дата рождения. Группа); СЕССИЯ (Номер. Оценка 1, Оценка 2, Оценка 3, Оценка 4, Результат): СТИПЕНДИЯ (Результат, Процент), Таблицы СТУДЕНТ И СЕССИЯ имеют совпадающие ключи (Номер), что дает возможность легко организовать связь между ними. Таблица СЕССИЯ имеет первичный ключ Номер и содержит внешний ключ Результат, который обеспечивает ее связь с таблицей СТИПЕНДИЯ. ВВЕРХ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|