ВВЕДЕНИЕ В ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ
История развития искуственного интеллекта
История развития искусственного интеллекта за рубежом
Идея создания искусственного подобия человеческого разума для решения сложных
задач моделирования мыслительной способности витала в воздухе с древнейших времен
[6,7].Впервые ее выразил Р.Луллий (ок.1235- ок.1315), который еще н XIV
в. пытался создать машину для решения различных задач на основе всеобщей классификации
понятий.
В XVIII в. Г.Лейбниц (1646 - 1716) и Р.Декарт (1596- 1650) независимо
друг от друга развили эту идею, предложив универсальные языки классификации
всех наук. Эти идеи легли в основу теоретических разработок в области создания
искусственного интеллекта.
Развитие искусственного интеллекта как научного направления стало возможным
только после создания ЭВМ. Это произошло в 40-х гг. XX в. В это же время
И.Винер (1894- 1964) создал свои основополагающие работы по новой
науке - кибернетике.
Термин искусственный интеллект (artificial intelligence) предложен в
1956 г. на семинаре с аналогичным названием в Станфордском университете (США).
Семинар был посвящен разработке логических, а не вычислительных задач. Вскоре
после признания искусственного интеллекта самостоятельной отраслью науки произошло
разделение на два основных направления: нейрокибернетику и кибернетику "черного
ящика". И только в настоящее время стали заметны тенденции к объединению
этихчастей вновь в единое целое.
Основную идею нейрокибернетики можно
сформулировать следующим образом. Единственный объект, способный мыслить,
- это человеческий мозг. Поэтому любое "мыслящее" устройство
должно каким-то образом воспроизводить его структуру.
Таким образом нейрокибериетика ориентирована на аппаратное моделирование
структур, подобных структуре мозга. Физиологами давно установлено, что
основой человеческого мозга является большое количество связанных между
собой и взаимодействующих нервных клеток - нейронов. Поэтому усилия нейрокибернетики
были сосредоточены на создании элементов, аналогичных нейронам, и их объединении
в функционирующие системы. Эти системы принято называть нейронными
сетями, или нейросетями.
Первые нейросети были созданы в конце 50-х гг. американскими учеными
Г.Розенблаттом и П.Мак-Кигюком. Это были попытки создать
системы, моделирующие человеческий глаз и его взаимодействие с мозгом.
Устройство, созданное ими, получило название перцептрона.
Оно умело различать буквы алфавита, но было чувствительно к их написанию,
например, буквы А, А и А для этого устройства были тремя
разными знаками. Постепенно в 70-80 гг. количество работ по этому направлению
искусственного интеллекта стало снижаться. Слишком неутешительны оказались
первые результаты. Авторы объясняли неудачи малой памятью и низким быстродействием
существующих в то время компьютеров.
Однако в середине 80-х гг. в Японии в рамках проекта разработки компьютера
V поколения, основанного на знаниях, был создан компьютерVI поколения,
или нейрокомпьютер. К этому времени ограничения по памяти и быстродействию
были практически сняты. Появились транспьютеры
- параллельные компьютеры с большим количеством процессоров. От транспьютеров
был один шаг до нейрокомпьютеров,
моделирующих структуру мозга человека. Основная область применения нейрокомпьютеров
- распознавание образов.
В настоящее время используются три подхода к созданию нейросетей:
аппаратный - создание специальных компьютеров, плат расширения,
наборов микросхем, реализующих все необходимые алгоритмы,
программный - создание программ н инструментариев, рассчитанных
на высокопроизводительные компьютеры. Сети создаются в памяти компьютера,
всю работу выполняют его собственные процессоры;
гибридный - комбинация первых двух. Часть вычислений выполняют
специальные платы расширения (сопроцессоры), часть - программные средства.
В основу кибернетики "черного ящика"
лег принцип, противоположный нейрокибернетике. Не имеет значения, как
устроено "мыслящее" устройство. Главное, чтобы на заданные входные
воздействия оно реагировало так же, как человеческий мозг.
Это направление искусственного интеллекта было ориентировано на поиски
алгоритмов решения интеллектуальных задач на существующих моделях компьютеров.
В 1956 -1963 гг. велись интенсивные поиски моделей и алгоритма человеческого
мышления и разработка первых программ. Оказалось, что ни одна из существующих
наук - философия, психология, лингвистика - не может предложить такого
алгоритма. Тогда кибернетики предложили создать собственные модели. Были
созданы и опробованы различные подходы.
В конце 50-х гг. родилась модель лабиринтного
поиска. Этот подход представляет задачу как некоторый граф,
отражающий пространство состояний, и в этом графе проводится поиск оптимального
пути от входных данных к результирующим. Была проделана большая работа
по разработке этой модели, но в решении практических задач идея большого
распространения не получила,
Начало б0-х гг. - эпоха эвристического программирования.
Эвристика - правило, теоретически
не обоснованное, но позволяющее сократить количество переборов в пространстве
поиска. Эвристическое программирование - разработка стратегии действий
на основе известных, заранее заданных эвристик.
В 1963- 1970 гг. к решению задач стали подключать методы математической
логики. На основе метода резолюций, позволившего автоматически
доказывать теоремы при наличии набора исходных аксиом, в 1973 г. создается
язык Пролог.
Существенный прорыв в практических приложениях искусственного интеллекта
произошел в середине 70-х гг., когда на смену поискам универсального алгоритма
мышления пришла идея моделировать конкретные знания специалистов-экспертов.
В США появились первые коммерческие системы, основанные на знаниях,
или экспертные системы.
Пришел новый, подход к решению задач искусственного интеллекта - представление
знаний.Созданы MYCIN и DENDRAL - ставшие уже классическими экспертные
системы для медицины и химии. Объявлено несколько глобальных программ
развития интеллектуальных технологий - ESPRIT (Европейский Союз). DARPA
(министерство обороны США), японский проект машин V поколения.
Начиная с середины 80-х гг. происходит коммерциализация искусственного интеллекта.
Растут ежегодные капиталовложения, создаются промышленные экспертные системы.
Растет интерес к самообучающимся системам.
История развития искусственного интеллекта в России
В 1954 г. в МГУ под руководством профессора А.А.Ляпунова (1911 - 1973)
начал свою работу семинар "Автоматы и мышление" . В этом семинаре
принимали участие крупнейшие физиологи, лингвисты, психологи, математики. Принято
считать, что именно в это время родился искусственный интеллект в России. Как
и за рубежом, выделились направления нейрокибернетики и кибернетики "черного
ящика".
Среди наиболее значимых результатов, полученных отечественными учеными, следует
отметить алгоритм "Кора" М.Бонгарда, моделирующий деятельность
человеческого мозга при распознавании образов (60-е гг.).
В 1945- 1964 гг. создаются отдельные программы и исследуется поиск решения
логических задач. В Ленинграде (ЛОМИ - Ленинградское отделение математического
института им. В.А.Стеклова) создается программа, автоматически доказывающая
теоремы (АЛИЕВ ЛОМИ). Она основана на оригинальном обратном выводе С.Ю.Маслова,
аналогичном методу резолюций Робинсона.
В 1965- 1980 гг. получает развитие новая наука - ситуационное
управление (соответствует представлению знаний в западной
терминологии). Основоположник этой научной школы - профессор Д.А.Поспелов.
Разработаны специальные модели представления ситуаций - представления
знаний.
В 1980- 1990 гг. проводятся активные исследования в области представления знаний,
разрабатываются языки представления знаний, экспертные системы (более 300).
В Московском государственном университете создается язык РЕФАЛ.
В 1988 г. создается АИИ - Ассоциация искусственного интеллекта. Ее членами
являются более 300 исследователей. Президент Ассоциации - Д.А.Поспелов.
Крупнейшие центры - в Москве, Петербурге, Переславле-Залесском, Новосибирске.
В рамках Ассоциации проводится большое количество исследований,собираются конференции,
издается журнал. Уровень теоретических исследований по искусственному интеллекту
в России ничуть не ниже мирового. К сожалению, начиная с 1975 г- на развитии
этого направления сказалось прогрессирующее отставание в технологии. На данный
момент отставание в области промышленных интеллектуальных систем составляет
порядка 5-7 лет.
НАПРАВЛЕНИЯ РАЗВИТИЯ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Искусственный интеллект - это одно из направлений информатики, цель которого
разработка аппаратно-программных средств, позволяющих пользователю-непрограммисту
ставить и решать свои задачи, традиционно считающиеся интеллектуальными,
общаясь с ЭВМ на ограниченном подмножестве естественного языка.
Представление знаний и разработка систем, основанных на знаниях
Это основное направление искусственного интеллекта. Оно связано с разработкой
моделей представления знаний, созданием баз знаний, образующих ядро экспертных
систем (ЭС). В последнее время включает в себя модели и методы извлечения и
структурирования знаний и сливается с инженерией знаний (см. гл. 17).
Игры и творчество
Традиционно искусственный интеллект включает в себя игровые интеллектуальные
задачи - шахматы, шашки, го. В основе лежит один из ранних подходов -
лабиринтная модель плюс эвристики. Сейчас это скорее коммерческое направление,
так как в научном плане эти идеи считаются тупиковыми.
Разработка естественноязыковых интерфейсов и машинный перевод
В 50-х п. одной из популярных тем исследований искусственного интеллекта
являлась область машинного перевода. Первая программа в этой области -
переводчик с английского языка на русский. Первая идея - пословный перевод,
оказалась неплодотворной. В настоящее время используется более сложная
модель, включающая анализи синтез естественно-языковых сообщений, которая
состоит из нескольких блоков. Для анализа это:
морфологический анализ - анализ слов
в тексте;
синтаксический анализанализ
предложений, грамматики и связей между словами;
семантический анализ - анализ
смысла каждого предложения на основе некоторой предметно-ориентированной
базы знаний;
прагматический анализ - анализ
смысла предложений в окружающем контексте на основе собственной базы знаний.
Синтез включает аналогичные этапы, но несколько в другом порядке,
Распознавание образов
Традиционное направление искусственного интеллекта, берущее начало у самых
его истоков. Каждому объекту ставится в соответствие матрица признаков, по которой
происходит ею распознавание. Это направление близко к машинному обучению, тесно
связано с нейрокичернетикой.
Новые архитектуры компьютеров
Это направление занимается разработкой новых аппаратных решений и архитектур,
направленных на обработку символьных и логических данных. Создаются Пролог-
и Лисп-машины, компьютеры V и VI поколений. Последние разработки посвящены компьютерам
баз данных и параллельным компьютерам.
Интеллектуальные роботы
Роботы - это электромеханические устройства, предназначенные для
автоматизации человеческого труда.
Идея создания роботов исключительно древняя. Само слово появилось в 20-х
гг. Его автор - чешский писатель Карел Чапек. Со времени создания сменилось
несколько поколений роботов.
Роботы с жесткой схемой управления. Практически все современные промышленные
роботы принадлежат к первому поколению. Фактически это программируемые манипуляторы.
Адаптивные роботы с сенсорными устройствами. Есть образцы таких роботов,
но в промышленности они пока не используются.
Самоорганизующиеся, или интеллектуальные, роботы. Это конечная
цель развития робототехники. Основная проблема при создании интеллектуальных
роботов - проблема машинного зрения-
В настоящее время в мире изготавливается более 60 тыс. роботов в год.
Специальное программное обеспечение
В рамках этого направления разрабатываются специальные языки для решения
задач невычислительного плана. Эти языки ориентированы на символьную обработку
информации - LISP, PROLOG, SMALLTALK, РЕФАЛ и др. Помимо этого создаются
пакеты прикладных программ, ориентированные на промышленную разработку
интеллектуальных систем, или программные инструментарии искусственного
интеллекта, например KEE, ARTS[10].Достаточно популярно создание так называемых
пустых экспертных систем, или "оболочек", - BXSYS, Ml и др.,
в которых можно наполнять базы знаний, создавая различные системы.
Обучение и самообучение
Активно развивающаяся область искусственного интеллекта. Включает модели, методы
и алгоритмы, ориентированные на автоматическое накопление знаний на основе анализа
и обобщения данных. Включает обучение по примерам (или индуктивное), а также
традиционные подходы распознавания образов.
ДАННЫЕ И ЗНАНИЯ
При изучении интилектуальных систем традиционно возникает вопрос - что
же такое знания и чем они отличаются от обычных данных, десятилетиями
обрабатываемых ЭВМ. Можно предложить несколько рабочих операций, в рамках
которых это становится очевидным.
Данные - это отдельные
факты, характеризующие объекты, процессы и явления в предметной области,
а также их свойства.
При обработке на ЭВМ данные трансформируются, условно проходя следующие этапы:
данные как результат измерений и наблюдений;
данные на материальных носителях информации (таблицы, протоколы, справочники;
модели (структуры) данных в виде диаграмм, графиков, функций;
данные в компьютере на языке описания данных;
базы данных на машинных носителях.
Знания связаны с данными, основываются на них, но представляют результат мыслительной
деятельности человека, обобщают его опыт, полученный в ходе выполнения какой-либо
практической деятельности. Они получаются эмпирическим путем.
Знания - это выявленные
закономерности предметной области (принципы, связи, законы), позволяющие
решать задачи в этой области. При обработке на ЭВМ знания трансформируются
аналогично данным:
знания в памяти человека как результат мышления;
материальные носители знаний (учебники, методические пособия);
поле знаний - условное
описание основных объектов предметной области, их атрибутов и закономерностей,
их связывающих;
знания, описанные на языках представления знаний (продукционные языки,
семантические сети, фреймы - см. далее);
базы знаний.
Часто используются такие определения знаний:
знания - это хорошо структурированные данные, или данные о данных,
или метаданные.
Существует множество способов определять понятия. Один из широко применяемых
способов, основан на идее интенсионала. Интенсионал понятия - это
определение через понятие более высокого уровня абстракции с указанием
специфических свойств. Этот способ определяет знания. Другой способ определяет
понятие через перечисление понятий более низкого уровня иерархии или фактов,
относящихся к определяемому. Это есть определение через данные, или экстенсионал
понятия.
Пример 16.1. Понятие "персональный компьютер". Его интенсионал:
ЇПерсональный компьютер - это дружественная ЭВМ, которую можно поставить
на стол и купить менее чем за $2000 - 3000".
Экстенсионал этого понятия: "Персональный компьютер - это Mac, IBM
PC, Sinkler...".
Для хранения данных используются базы данных (для них характерны большой
объем и относительно небольшая удельная стоимость информации), для хранения
знаний - базы знаний (небольшого объема, но исключительно дорогие информационные
массивы). База знаний - основа любой интеллектуальной системы.
Знания могут быть классифицированы по следующим категориям:
- поверхностные - знания
о видимых взаимосвязях между отдельными событиями и фактами в предметной
области;
- глубинные - абстракции,
аналогии, схемы, отображающие структуру и процессы в предметной области.
Современные экспертные системы работают в основном споверхностными знаниями.
Это связано с тем, что на данный момент нет адекватных моделей, позволяющих
работать с глубинными знаниями.
Кроме того, знания можно разделить на процедурные
и декларативные.
Исторически первичными были процедурные знания, т.е. знания, "растворенные"
в алгоритмах. Они управляли данными. Для их изменения требовалось изменять
программы. Однако с развитием искусственного интеллекта приоритет данных
постепенно изменялся, и все большая часть знаний сосредоточивалась в структурах
данных (таблицы, списки, абстрактные типы данных), т.е. увеличивалась
роль декларативных знаний.
Сегодня знания приобрели чисто декларативную форму, т.е. знаниями считаются
предложения, записанные на языках представления знаний, приближенных к естественному
и понятных неспециалистам.
Существуют десятки моделей (или языков) представления знаний для различных
предметных областей. Большинство из них может быть сведено к следующим классам:
- формальные логические модели.
МОДЕЛИ ПРЕДСТАВЛЕНИЯ ЗНАНИЙ
Продукционная модель
Продукционная модель,
или модель, основанная на правилах, позволяет представить знания в виде
предложений типа: Если (условие), то (действие).
Под, условием понимается некоторое предложение-образец, по которому
осуществляется поиск в базе знаний, а под действием - действия,
выполняемые при успешном исходе поиска (они могут быть промежуточными,
выступающими далее как условия, и терминальными или целевыми, завершающими
работу системы).
При использовании продукционной модели база знаний состоит из набора
правил, Программа, управляющая перебором правил, называется машиной вывода.
Чаще всего вывод бывает прямой (от данных к поиску цели) или обратный
(от цели для ее подтверждения - к данным). Данные - это исходные факты,
на основании которых запускается машина вывода - программа, перебирающая
правила из базы.
Пример 16.2. Имеется фрагмент базы знаний из двух правил:
/71: Если "отдых - летом" и "человек - активный",
то "ехать в горы",
/72: Если "любит солнце", то "отдых летом",
Предположим, в систему поступили данные - "человек активный"
и "любит "солнце"
Прямой вывод - исходя из данных, получить ответ.
1-й проход.
Шаг 1. Пробуем П1, не работает (не хватает данных "отдых - летом").
Шаг 2. Пробуем П2, работает, в базу поступает факт "отдых - летом".
2-й проход.
Шаг 3. Пробуем /7/, работает, активируется цель "ехать в горы",
которая и выступает как совет, который дает ЭС.
Обратный вывод - подтвердить выбранную цель при помощи имеющихся правил
и данных.
1-й проход.
Шаг 1. Цель - "ехать в горы": пробуем П1 - данных, "отдых
- летом" нет, они становятся новой целью, и ищется правило, где она
в правой части.
Шаг 2. Цель "отдых - летом": правило П2 подтверждает цель и
активирует ее.
2-й проход.
Шаг 3. Пробуем П1, подтверждается искомая цель.
Продукционная модель чаще всего применяется в промышленных экспертных системах.
Она привлекает разработчиков своей наглядностью, высокой модульностью, легкостью
внесения дополнений и изменений и простотой механизма логического вывода.
Имеется большое число программных средств, реализующих продукционный
подход (язык OPS 5 [8]; "оболочки" или "пустые" ЭС
- EXSYS [10], ЭКСПЕРТ [2]; инструментальные системы 11ИЭС [1!] и СПЭИС
[3] и др.), а также промышленных ЭС на его основе (ФИАКР [8]) и др.
Семантические сети
Термин семантическая
означает смысловая, а сама семантика - это наука, устанавливающая отношения
между символами и объектами, которые они обозначают, т.е. наука, определяющая
смысл знаков,
Семантическая сеть- это ориентированный граф, вершины которого - понятия,
а дуги - отношения между ними.
Понятиями обычно выступают абстрактные или конкретные объекты,
а отношения - это связи типа: "это" ("is"),
"имеет частью" ("has part"), "принадлежит",
"любит". Характерной особенностью семантических сетей является
обязательное наличие трех типов отношений:
Можно ввести несколько классификаций семантических сетей. Например, по количеству
типов отношений:
- однородные (с единственным типом отношений);
- неоднородные (с различными типами отношений).
По типам отношений:
- бинарные (в которых отношения связывают два объекта);
- парные (в которых есть специальные отношения, связывающие более двух понятий).
Наиболее часто в семантических сетях используются следующие отношения:
- связи типа "часть-целое" ("класс-подкласс", "элемент-множество"
и т.п.);
- функциональные связи (определяемые обычно глаголами "производит",
"влияет"...);
- количественные (больше, меньше, равно...);
- пространственные (далеко от, близко от, за, под, над...);
- временные (раньше, позже, в течение...);
- атрибутивные связи (иметь свойство, иметь значение...);
- логические связи (и, или, не) и др.
Проблема поиска решения в базе знаний типа семантической сети сводится к задаче
поиска фрагмента сети, соответствующего некоторой подсети, соответствующей поставленному
вопросу.
Пример 16.3. На рис. 16.1 изображена семантическая
сеть. В качестве вершин понятия: Человек, Иванов, Волга. Автомобиль, Вид транспорта.
Двигатель.
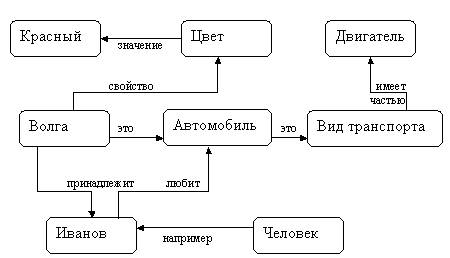
Рис.16.1. Семантическая сеть.
Основное преимущество этой модели - в соответствии современным представлениям
об организации долговременной памяти человека. Недостаток модели - сложность
поиска вывода на семантической сети.
Для реализации семантических сетей существуют специальныесетевые языки,
например NET[12] и др. Широко известны экспертныесистемы, использующие
семантические сети в качестве языка представления знаний - PROSPECTOR,
CASNBT, TORUS [8,10].
Фреймы
Фрейм (англ. frame - каркас
или рамка) предложен М.Минским в 70-е гг. Как структура знаний для восприятия
пространственных сцен. Эта модель, как и семантическая сеть, имеет глубокое
психологическое обоснование.
Под фреймом понимается абстрактный образ или ситуация. В психологии и
философии известно понятие абстрактного образа. Например, слово "комната"
вызывает у слушающих образ комнаты: "жилое помещение с четырьмя стенами,
полом, потолком, окнами и дверью, площадью 6-20 м2 ".
Из этого описания ничего нельзя убрать (например, убрав окна мы получим
уже чулан, а не комнату), но в нем есть "дырки", или "слоты",
- это незаполненные значения некоторых атрибутов -количество окон, цвет
стен, высота потолка. покрытие пола и др.
В теории фреймов такой образ называется фреймом. Фреймом называется также и
формализованная модель для отображения образа.
Структуру фрейма можно представить так;
ИМЯ ФРЕЙМА :
(имя 1-го слота: значение 1-го слота),
(имя 2-го слота: значение 2-го слота),
- - - -
(имя N-го слота: значение N-гo слота).
Ту же запись представим в виде таблицы, дополнив двумя столбцами.
В таблице дополнительные столбцы предназначены для описания тина слота и возможного
присоединения к тому или иному слоту специальных процедур, что допускается в
теории фреймов. В качестве значения слота может выступать имя другого фрейма;
так образуют сети фреймов.
Различают фреймы-образцы,
или прототипы, хранящиеся в базе знаний, и фреймы-экземпляры,
которые создаются для отображения реальных ситуаций на основе поступающих
данных.
Модель фрейма является достаточно универсальной, поскольку позволяет отобразить
все многообразие знаний о мире через:
- фреймы-структуры,
для обозначения объектов и понятий (заем, залог, вексель);
- фреймы-роли (менеджер,
кассир, клиент);
- фреймы-сценарии
(банкротство, собрание акционеров, празднование именин);
- фреймы-ситуации
(тревога, авария, рабочий режим устройства) и др.
Важнейшим свойством теории фреймов является заимствованное из теории семантических
сетей наследование свойств. И во фреймах, и в семантических сетях наследование
происходит по АКО-связям (A-Kind-Of = это). Слот АКО указывает
на фрейм более высокого уровня иерархии, откуда неявно наследуются, т.е. переносятся,
значения аналогичных слотов.
Пример 16.4. Например, в сети фреймов на рис. 16.2 понятие "ученик"
наследует свойства фреймов "ребенок" и "человек",
которые находятся на более высоком уровне иерархии. Гак, на вопрос: "Любят
ли ученики сладкое?" Следует ответ: "Да", так как ним свойством
обладают все дети, что указано во фрейме "ребенок". Наследование
свойств может быть частичным, так, возраст для учеников не наследуется
ил фрейма "ребенок", поскольку указан явно в своем собственном
фрейме.
Основным преимуществом фреймов как модели представления знаний является способность
отражать концептуальную основу организации памяти человека [13], а также гибкость
и наглядность.
Специальные языки представления знаний в сетях фреймов FRL (Frame Representation
Language) [1] и другие позволяют эффективно строить промышленные ЭС. Широко
известны такие фреймо-ориентированные экспертные системы, как ANALYST, МОДИС
[3,8].
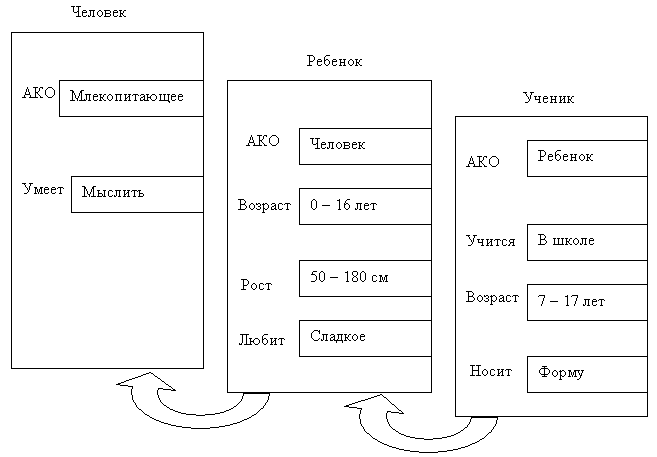
Рис. 16.2. Сеть фреймов
Формальные логические модели
Традиционно в представлении знаний выделяют формальные логические
модели, основанные на классическом исчислении предикатов 1 порядка,
когда предметная область или задача описывается в виде набора аксиом.
Мы же опустим описание этих моделей по следующим причинам. Исчисление
предикатов 1 порядка в промышленных экспертных системах практически не
используется. Эта логическая модель применима в основном в исследовательских
"игрушечных" системах, так как предъявляет очень высокие требования
и ограничения к предметной области.
В промышленных же экспертных системах используются различные ее модификации
и расширения, изложение которых выходит за рамки данного учебника.
ВВЕРХ
| 
